Speech framework in iOS 10
At WWDC 2016, Apple introduced the Speech framework, an API which allows app developers to incorporate speech recognition in their app. The exciting fact about this API is that it can perform real time or recorded speech recognition, in almost 50 languages.
Nowadays, many speech recognition frameworks are available, but most of them are expensive.
In this post, we will see how to use the Speech framework in a live scenario, using the microphone, but also by reading a file (audio or video) as a data input. First let’s see what we need to begin.
Asking for permission
To start, import the Speech framework and conform to the SFSpeechRecognizerDelegate protocol.
import Speech
public class MySpeechObject: SFSpeechRecognizerDelegate {}In order to perform speech recognition using the framework, it is mandatory to first ask for the user permission. The framework is based on SiriKit, all data are sent and processed on Apple’s servers. You need to inform the user and ask its permission.
Add a property into Info.plist. Set your custom message for the Privacy — Speech Recognition Usage Description key.
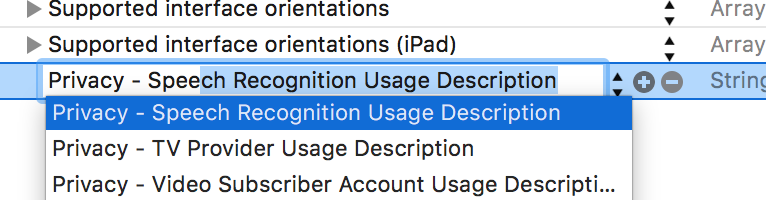
Now we need to actually ask the permission. I recommend calling this method only when you need to trigger speech recognition.
private func askForSpeechRecognitionAuthorization() {
SFSpeechRecognizer.requestAuthorization { authStatus in
var enabled: Bool = false
var message: String?
switch authStatus {
case .authorized:
enabled = true
case .denied:
enabled = false
message = "User denied access to speech recognition"
case .restricted:
enabled = false
message = "Speech recognition restricted on this device"
case .notDetermined:
enabled = false
message = "Speech recognition not yet authorized"
}
/* The callback may not be called on the main thread. Add an operation to the main queue if you want to perform action on UI. */
OperationQueue.main.addOperation {
// here you can perform UI action, e.g. enable or disable a record button
}
}
}Getting ready
We declare two objects, required to perform speech recognition:
private var speechRecognizer: SFSpeechRecognizer!
private var recognitionTask: SFSpeechRecognitionTask?-
speechRecognizier: handles speech recognition -
recognizitionTask: gives the result of the recognition ; the task can be cancelled or stopped
We need to let the recognizer know what language the user is speaking and to make it our delegate:
speechRecognizer = SFSpeechRecognizer(locale: Locale.init(identifier: "en-US"))!
speechRecognizer.delegate = selfConfiguration was pretty simple, now let’s see input data!
Are you listening?
Like speech recognition, user’s permission is required to use the microphone. Add a new property into Info.plist, Privacy — Microphone Usage Description and provide a message.

Start by adding these two objects:
private var recognitionRequest: SFSpeechAudioBufferRecognitionRequest?
private let audioEngine = AVAudioEngine()-
recognitionRequest: handles the speech recognition request and provides an audio source (buffer) to the speech recognizer -
audioEngine: provides your audio input, here the microphone
Complete with this piece of code:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
private func startRecording() throws {
if let recognitionTask = self.recognitionTask {
recognitionTask.cancel()
self.recognitionTask = nil
}
let audioSession = AVAudioSession.sharedInstance()
try audioSession.setCategory(AVAudioSessionCategoryRecord)
try audioSession.setMode(AVAudioSessionModeMeasurement)
try audioSession.setActive(true, with: .notifyOthersOnDeactivation)
guard let inputNode = audioEngine.inputNode else { fatalError("Audio engine has no input node") }
self.recognitionRequest = SFSpeechAudioBufferRecognitionRequest()
guard let recognitionRequest = recognitionRequest else { fatalError("Unable to created a SFSpeechAudioBufferRecognitionRequest object") }
self.recognitionRequest.shouldReportPartialResults = true
self.recognitionTask = self.speechRecognizer.recognitionTask(with: recognitionRequest) { result, error in
var isFinal = false
if let result = result {
self.textView.text = result.bestTranscription.formattedString
isFinal = result.isFinal
}
if error != nil || isFinal {
self.audioEngine.stop()
inputNode.removeTap(onBus: 0)
self.recognitionRequest = nil
self.recognitionTask = nil
self.recordButton.isEnabled = true
}
}
let recordingFormat = inputNode.outputFormat(forBus: 0)
inputNode.installTap(onBus: 0, bufferSize: 1024, format: recordingFormat) { (buffer: AVAudioPCMBuffer, when: AVAudioTime) in
self.recognitionRequest?.append(buffer)
}
audioEngine.prepare()
try audioEngine.start()
}
Let’s break down the parts.
- Lines 3-6: cancel current speech recognition task if one is running
- Lines 8-12: prepare for the audio recording,
AVAudioEngineis required to process the input audio signals - Lines 14-16: initialize speech recognition request ; here we choose to retrieve partial results as soon as they’re available (when words are recognized), because it can take some time (several seconds) for the server to finalize the result of recognition and finally send it back
- Lines 18: set the speech recognition task with the request: the completion handler will be called each time its state change (cancelled, new input, final results, etc.)
- Lines 22-25: check if partial results are available and display it
- Lines 27-33: final results: stop microphone and clean speech recognition objects
- Lines 36-42: add microphone input to speech recognition request and start microphone
Finally, we launch the recognition. Assume we bind this method to an UIButton:
@IBAction func recordButtonTapped() {
if audioEngine.isRunning {
audioEngine.stop()
recognitionRequest?.endAudio()
recordButton.isEnabled = false
} else {
try? startRecording()
}
}Start only occurs when microphone is not already running, so we only have one task running at a time.
What are you saying?

The sample project above (based on Apple’s sample code SpeakToMe) is available on GitHub.
Listen to this
It is also possible to use file as data input. Even if the API wasn’t designed for that purpose, it can be useful to transcript lyrics, podcast or generate live subtitles of a video.
And it does not need much changes to work. Update the current code with these:
private var recognitionRequest: SFSpeechURLRecognitionRequest?
private func startRecording() throws {
if let recognitionTask = recognitionTask {
recognitionTask.cancel()
self.recognitionTask = nil
}
let path = Bundle.main.path(forResource: "your-file", ofType: "mp3")
if let path = path {
let url = URL(fileURLWithPath: path)
recognitionRequest = SFSpeechURLRecognitionRequest(url: url)
}
guard let recognitionRequest = recognitionRequest else { fatalError("Unable to created a SFSpeechURLRecognitionRequest object") }
recognitionRequest.shouldReportPartialResults = true
recognitionTask = speechRecognizer.recognitionTask(with: recognitionRequest) { result, error in
var isFinal = false
if let result = result {
self.textView.text = result.bestTranscription.formattedString
isFinal = result.isFinal
}
if error != nil || isFinal {
self.recognitionRequest = nil
self.recognitionTask = nil
self.recordButton.isEnabled = true
}
}
}
@IBAction func recordButtonTapped() {
if (self.recognitionTask?.state == .running) {
self.recognitionTask?.finish()
self.recognitionRequest = nil
self.recordButton.isEnabled = false
} else {
try! startRecording()
}
}Instead of the audio engine, the path of a file is required, it will be played internally automatically by the recognizer.
Task state is check instead of audio input state.
Last updated on 19th August 2019